

生成AI(GenAI)は、車両システムと統合することで、新しい機能以上のものをもたらします。単なるアップグレードの延長線上にあったように見える機能も、実際には学習し、進化し、自律的に動作するAIならではのシステムが組み込まれているのです。こういった革新の背後には、車両のライフサイクルを通じて車内に留まり、適応性があって動的な存在となる、新種のサプライチェーンリスクが生まれる危険性が秘められています。
イノベーションに後押しされ、ほとんどの自動車メーカー(OEM)は、現状、自社ブランドに採用するAIのトレーニングと供給を第三者パートナーに依存しています。しかし、このやり方は最も重要な転換について軽視した結果でもあるのです。AIはタスクを実行するだけでなく、行動を起こし、入力から学び、時間とともに適応します。そのため、サプライチェーンの中で生成AIは静的ソフトウェア部品ではなく、常に進化するリスクとして警戒する必要があるのです。
AIを導入する前に、そのAIモデルが「真に、安全、安心、信頼性が確保されているか」を検証する必要があります。
なぜ「進化するリスク」が現在のセキュリティモデルを突破するのか
従来のソフトウェアコンポーネントとは異なり、生成AIモデルの動作は、参照するデータ、受け取るプロンプト、および学習プロセスの継続的な進化に依存します。このため、OEMが慣れている従来の方法では、モデルを完全にテスト、監査、またはロックダウンすることが不可能です。
さらに深刻なのは、ほとんどの生成AIモデルは、OEMが閲覧したことのないデータを使用し、OEMの管理外のプロセスやツールで外部パートナーによってトレーニングや微調整されている点です。その結果、事前トレーニングデータ、モデルの調達、ファインチューニング(微調整)、導入、更新など、AIモデルライフサイクルのあらゆる段階にリスクが含まれます。多くの場合、これらのステップのいずれもOEMによって完全に管理されているわけではありません。
- モデルを構築した責任者は非公開であり、私たちはその身元について知り得ません。
- トレーニングデータのソースを確認・検証できません。
- 微調整(ファインチューニング)の過程で機密情報が漏洩したかどうかを確認できません。
- 最も重要な点は、モデルが学習と進化を続け、時間の経過とともにその動作が変化することです(これは記憶メカニズムを備えたAIシステムでのみ発生します)。
これらは仮定の懸念ではなくサプライチェーンにおける現実的で拡大する死角であり、ブラックボックスのような特性をもっています。
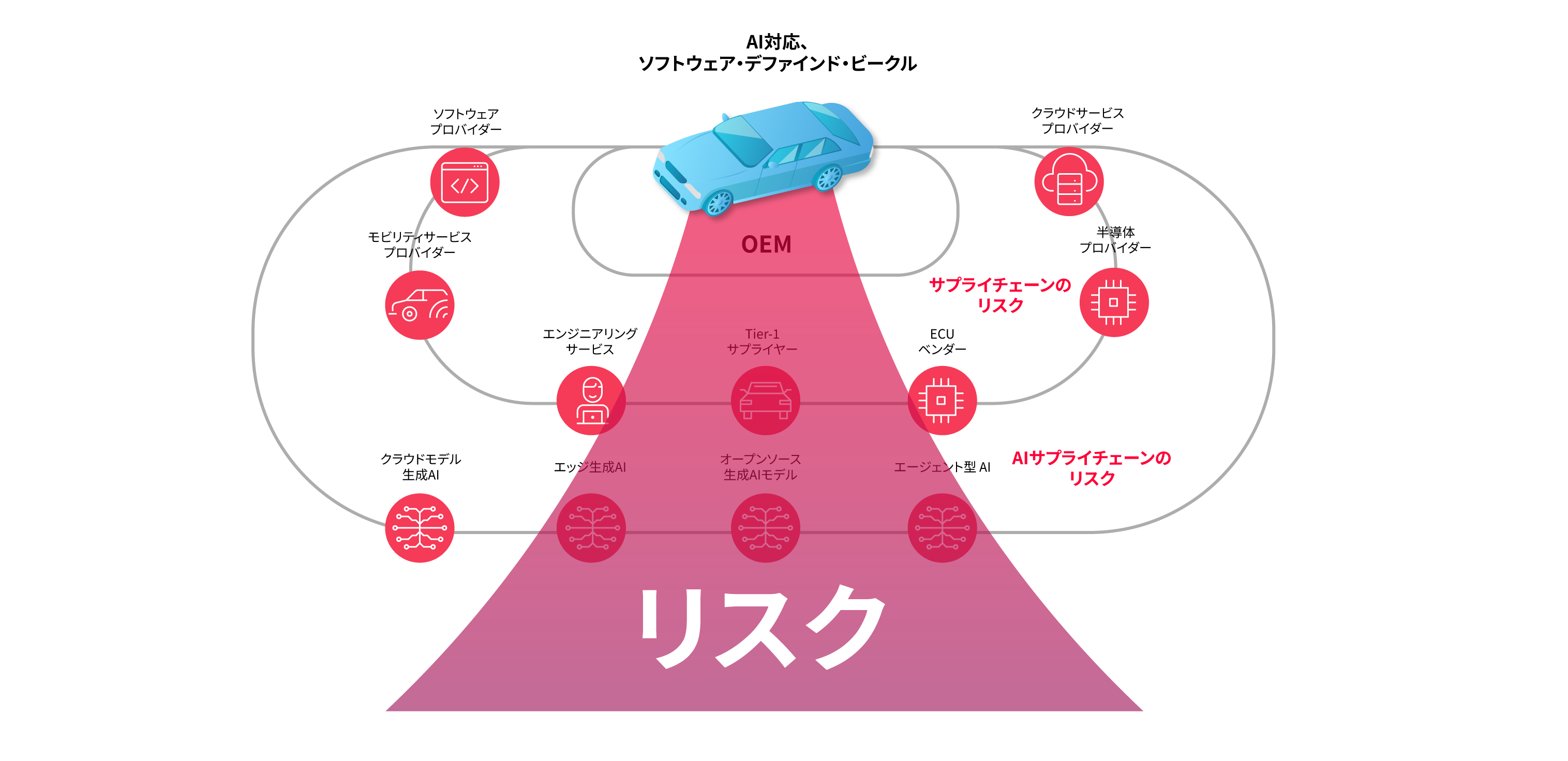
図1. AI = 新しいサプライチェーンのリスク
4つの生成AIモデルセキュリティリスク
自動車業界におけるAIの採用に関する当社の分析に基づき、生成AIモデルを車両システムに統合する際によく見落とされる4つの高影響リスクを特定しました。
1. モデルソースの盲点
人気や知名度は安全性やセキュリティを保証するものではありません。最も広く使用されているオープンソースモデルは、攻撃者にとって最も魅力的なターゲットでもあるのです。Enkrypt AI Safety Leaderboardによると、ダウンロード数が最も多いオープンソースのAIモデルの上位10件は、すべてNIST(米国立標準技術研究所)が定めたセキュリティリスクのしきい値を超えています。これらのリスクは理論上だけのものではありません——既に複数の現実の攻撃が報告されています。特に、Googleは最近、Vertex AIの脆弱性を修正しました。この脆弱性により、攻撃者が企業でトレーニングされたモデルを、抽出したり改ざんしたりする可能性がありました。
自動車環境では、攻撃者はこれらの脆弱性を悪用して、運転行動データ、ルート履歴、音声ログにアクセスしたり、車両の内部システムに侵入して機能を無効にしたりする可能性があります。
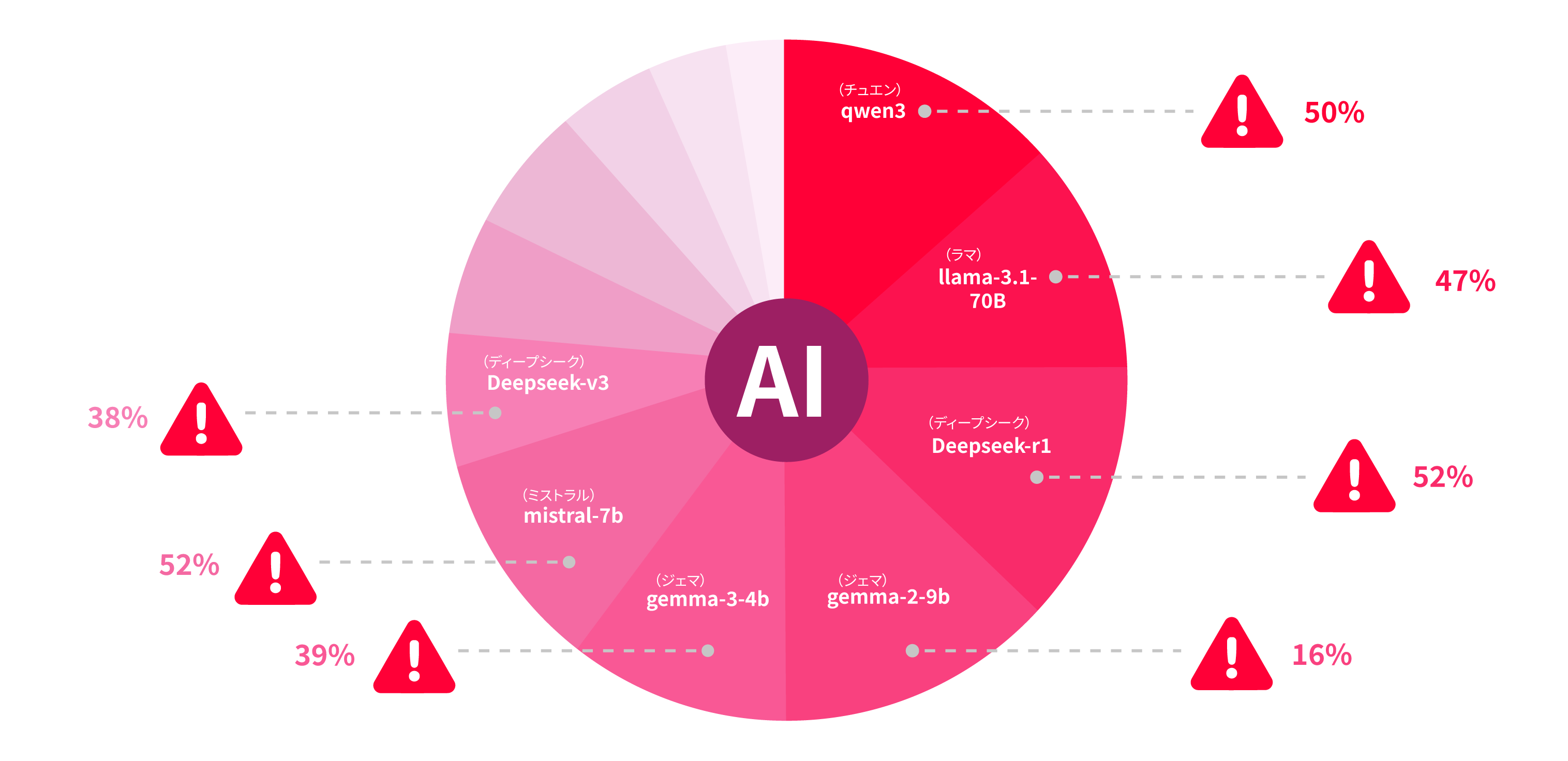
図2. Enkrypt AI Safety Leaderboard によると、ダウンロード数が最も多いオープンソースモデルの上位10件はすべて、何らかのサイバーセキュリティリスクを抱えている
2. トレーニングデータの汚染リスク
ファインチューニング工程における調整作業には、カスタマーサービスFAQ、メンテナンス記録、運転ログなど企業内部の機密性の高いデータが使用されることがあります。一部の組織では、AIプラットフォームから公開されているデータセットも利用しています。
しかし、この実践には重大なリスクが伴います。2024年、研究者はHugging Faceプラットフォーム上で100の悪意のあるコード実行モデルを発見しました。これらのモデルが使用されると、攻撃者が車両のシステム内でコードを実行し、機密データを暴露したり、より深刻な侵害を可能にしたりする可能性があります。この事例は、適切に検証されていない公開AIモデルが、深刻なサプライチェーン脅威となる可能性を警鐘しています。
さらに、調整作業に用いられたデータが適切にサニタイズされていなかったり、既に汚染されている場合、そのデータはモデルの長期メモリの一部となり、機密情報の漏洩や持続的なバックドアの生成を引き起こす可能性があります。
このリスクは、内部ワークフローやAPIロジックを意図せずに公開してしまう可能性があるChain-of-Thought (CoT)などの手法を使用する場合に特に高くなります。何万ものトレーニング例に数百の悪意のあるサンプルが混在しているだけで、動作に影響を与える可能性があります。
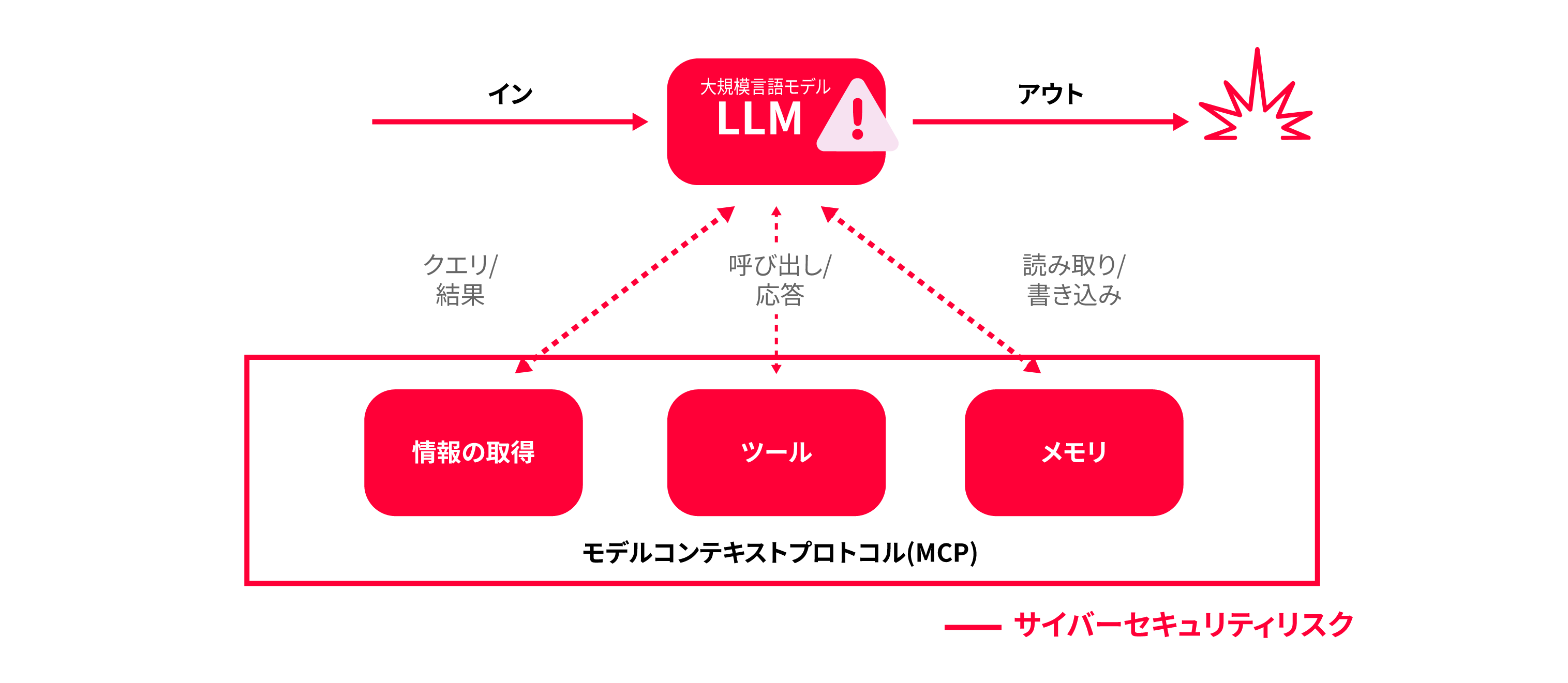
図3. 汚染されたモデルは、攻撃者によって操作され、意図しないまたは有害な動作を引き起こす可能性がある
3. モデル採用とプロキシガバナンスのギャップ
従来のソフトウェアコンポーネントは通常、プロダクションリリースされる際には、確立されたバージョン管理やビルド管理といったルールに準拠して行われるものです。しかしながらAIにおいては、モデルに採用している外部データやツールにアクセスするためのルールを定めたプロトコル - モデルコンテキストプロトコル(MCP)プロキシについて、まだ準拠すべき標準が確立しておらず、ガバナンス(統一された管理プロセス)が不足している場合があります。これにより、本番環境で展開されている特定のモデルバージョンの可視性が阻害され、追跡とリスク管理が困難になる可能性があります。
AI展開では、モデルコンテキストプロトコル(MCP)プロキシ(例:広く使用されているmcp-remoteツール)がアプリケーションとモデルの間で認証、リクエストのフォーマット、ネットワーク通信を処理します。AI専用のソフトウェア部品表(AI-SBOM)または同等の追跡メカニズムがない場合、開発運用チームは継続的な組み込みを行っていくうちに、知らず知らず古かったり信頼できなかったりするプロキシバージョンを意図せず展開してしまうリスクがあります。
このギャップは新たな攻撃ベクトルを開きます。例として、広く使用されているmcp-remoteツール(バージョン 0.0.5–0.1.15)に存在する重大なリモートコード実行脆弱性CVE-2025-6514があります。この脆弱性は、ツールが悪意のあるMCPサーバーに接続した場合にリモートコード実行を可能にし、攻撃者にホストの完全な制御権を与えてしまう可能性があります。
このような見落とし(意図した範囲を超えてモデル機能を採用し、バージョン履歴を厳格に管理しないこと)は、AIの導入においてモデルレベルの脅威を防止するため、厳格なガバナンス、SBOM実践、および署名付きモデル成果物の採用が急務であることを浮き彫りにしています。
4. 不正操作によるリスク
AIモデルまたはその隠れた「システムプロンプト」が漏洩した場合、攻撃者はモデルの「パスフレーズ」であるガードレールトークンの正確なシーケンスをリバースエンジニアリングし、安全チェックを回避するための敵対的なトークン(接尾辞)を作成できます。著名な例として、Imprompter攻撃が挙げられます。この攻撃では、一見ランダムな意味不明な文字列が、個人データを盗み出す悪意のある命令を隠蔽できることが明らかになりました。セキュリティリサーチャーは、個人情報を収集するプロンプトを、ランダムな文字の難読化されたサフィックスに変換し、オープンソースのチャットボット(LeChat、ChatGLM)に投入し、名前、ID番号、支払い情報などの窃取にほぼ80%の成功率を達成しました。
このような技術が音声アシスタントや車載インフォテインメント(IVI)システムに適用された場合、攻撃者はドライバーを誤導する偽のナビゲーションコマンドを発行したり、プライベートな音声会話を黙って記録または漏洩させたり、不正なアクションをトリガーしたりする可能性があります。いずれの場合も、安全性とプライバシーが侵害される可能性があります。
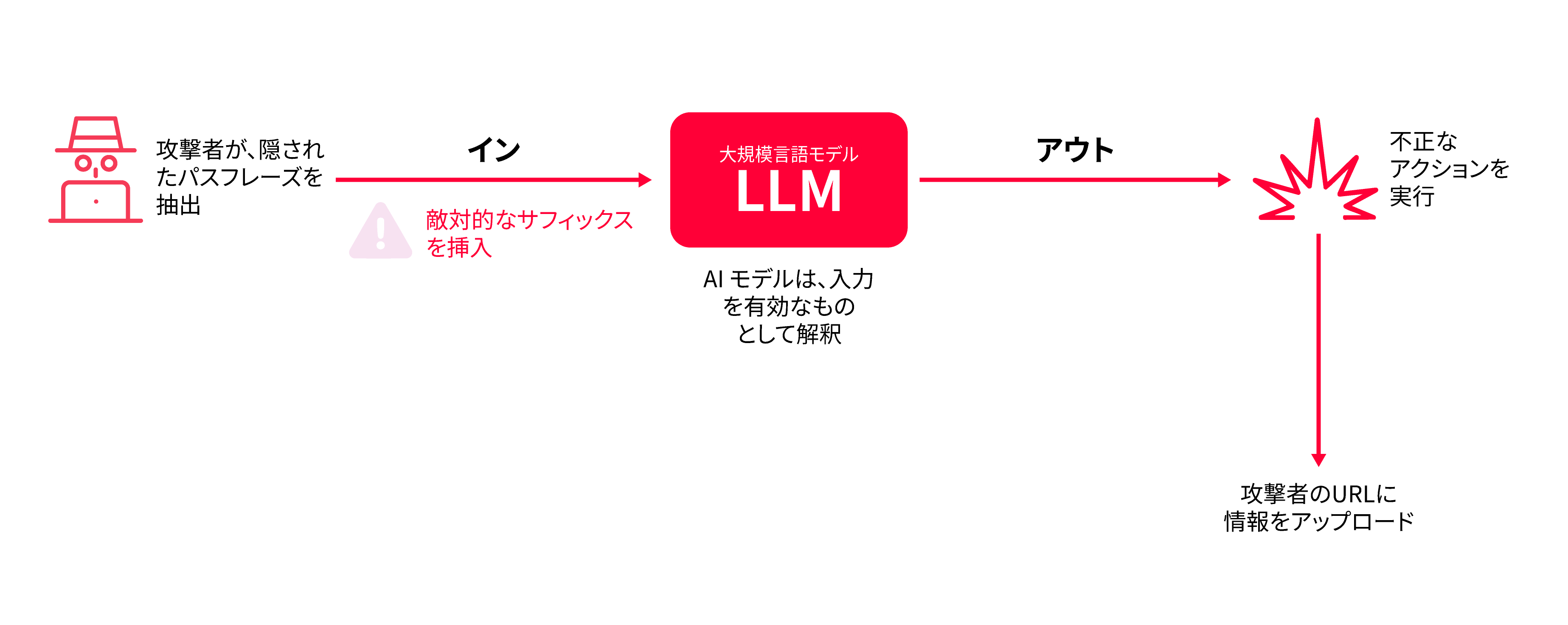
図4. 攻撃者が安全チェックを回避して不正な操作を実行する方法
ECUは厳格に検証されている。AIモデルも同様であるべき
AIの導入に対して避けるべきと言っているわけではありません。AIを導入し、適切なガバナンスとリスク管理を行う事で、AIについても他のサプライ品と同様にセキュリティを確保することがはじめて可能となります。車両内で生成AIが意思決定を行う場合、そのモデルはハードウェアやECUと同等の審査を受けるべきです。OEMは、以下のガバナンスを早期に実践すべきではないでしょうか。
- AI用のSBOMを構築する:モデルの起源、トレーニング履歴、リスク分類、脆弱性スキャン結果を文書化します。
- 堅牢なセキュリティテストを採用する:プロンプトインジェクションテストや敵対的堅牢性評価など、異常な動作を攻撃者の視点から検出するいわゆるレッドチームによるペネトレーションテストとリスク評価を実施します。
- モデルをサイバーセキュリティガバナンスに統合する:AIについても総合的なサイバーセキュリティリスク管理の一部として扱い、単一のダッシュボードを通じて可視化します。
生成AI(GenAI)はもはや単なるツールではありません。AIを搭載したソフトウェア・デファインド・ビークルの中核に深く組み込まれた、目に見えない、生きている、進化する存在です。スマートで革新的なコンポーネントである一方で、予期せぬリスクに対する安全性とセキュリティを確保するため、一貫した制御と監視を実施する必要があります。
さらに詳しい考察について、Max Chengによる『自動車業界におけるAI:サイバーセキュリティ・フレームワークの再定義』(英語)をご覧ください。


