

When Edge AI makes decisions in the cockpit, you need more than LLM-based guardrails

Latency
Cloud enforcement slows inference and degrades a smooth cockpit experience

Resource Overhead
Heavy guardrails consume memory and impact system performance

Integration Friction
Security not designed for edge AI delays SOP and struggles to keep up with emerging attack techniques
xPhinx: Secure Edge AI Interaction Without Delay or Overhead
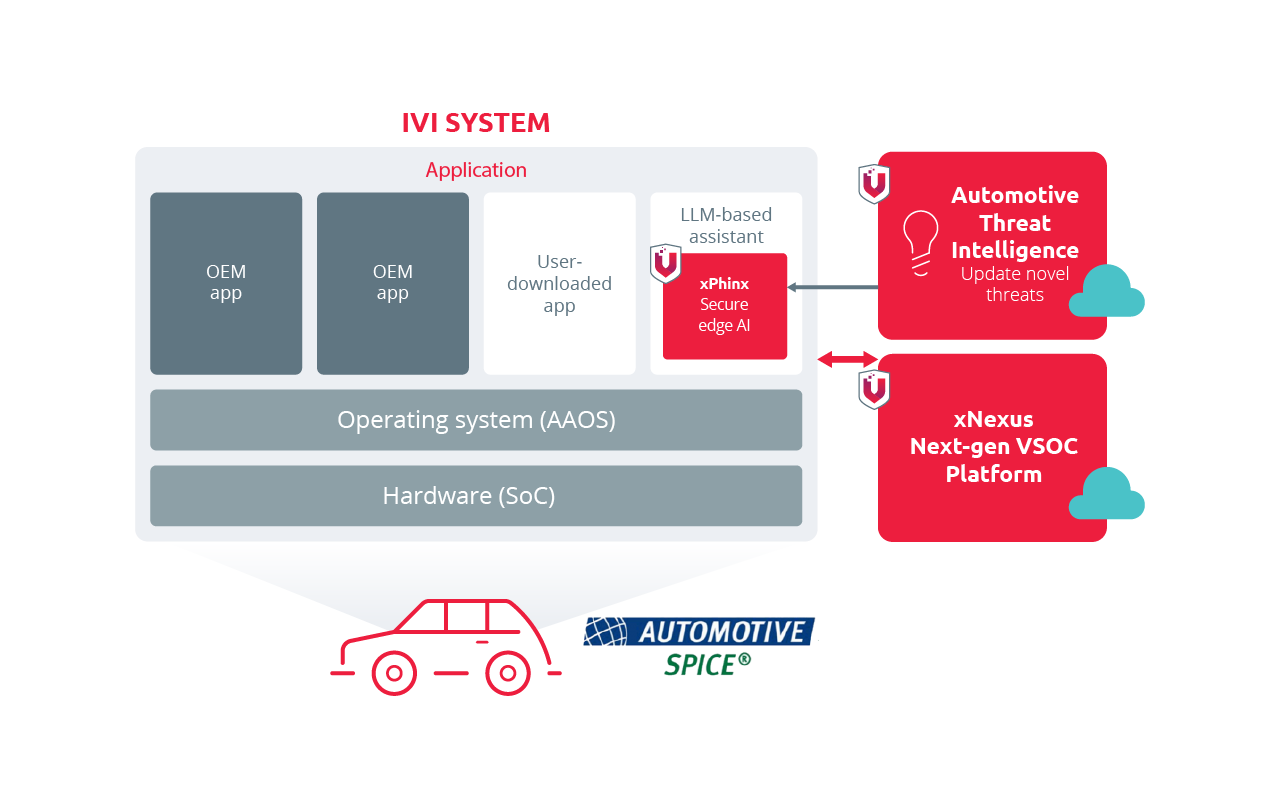
Risk-based AI Security Protection for In-Vehicle Edge AI
xPhinx protects in-vehicle edge AI and AI agents from prompt injection, jailbreak, unsafe behaviors, and data leakage, without slowing down AI intelligence cockpit interaction. Powered by automotive threat intelligence, xPhinx keeps pace with evolving prompt attacks and jailbreak techniques, inspecting and sanitizing LLM inputs and outputs to stop manipulated or unsafe behavior where AI decisions are made.
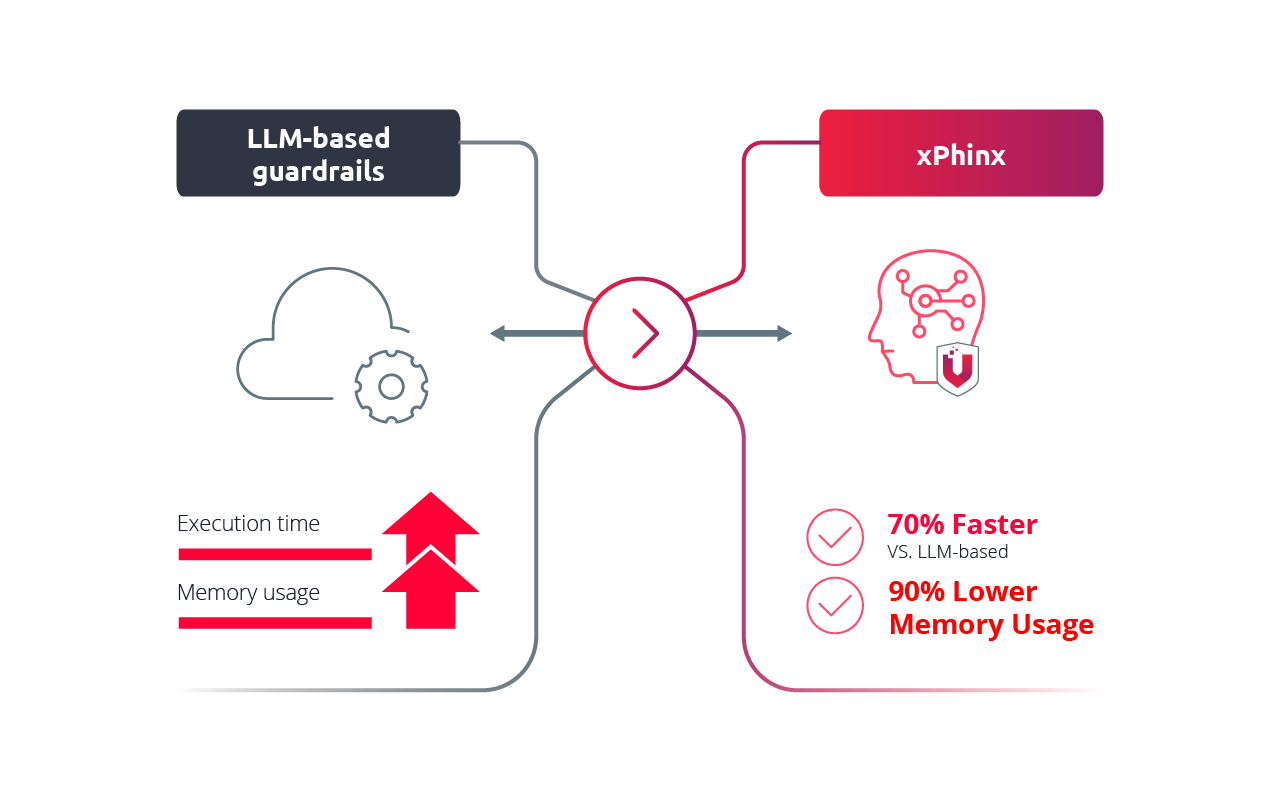
Enforce AI Security With Minimal Performance Impact
Unlike LLM-based guardrails, xPhinx is purpose-built for in-vehicle edge AI models (LLM/VLM). Its lightweight architecture operates directly on the device, achieving up to 70%* faster execution and up to 90%* lower memory usage. All without retraining, modifying, or upgrading existing AI models.
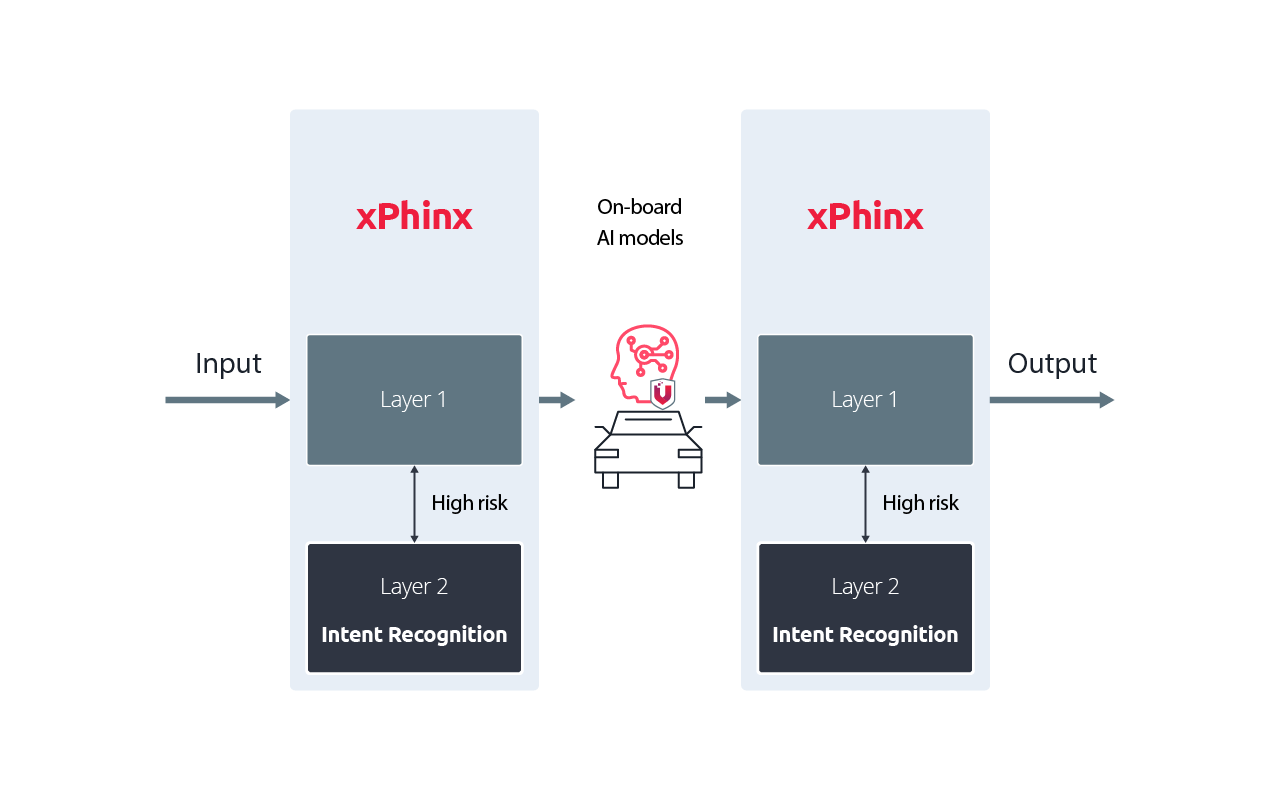
Context-Aware, Tiered Protection for In-Vehicle AI
xPhinx uses a dual-layer, risk-aware design: a lightweight first layer runs continuously, while deeper intent analysis is activated only when higher-risk behavior is detected. This approach delivers strong AI security without impacting AI application performance across diverse smart-cockpit applications. All VicOne edge software aligns with the ASPICE CL2 product and project requirements.
Built for Vehicles
xPhinx vs. LLM-Based Guardrails
Cloud and LLM-based guardrails were designed for content and service safety, not for an edge AI-driven smart cockpit that directly influences vehicle behavior and seamless user interaction.
| LLM-Based Guardrails | xPhinx | |
|---|---|---|
| Designed for Edge AI smart cockpit | Limited; high cost & latency | Yes |
| Privacy and data residency | Data send to cloud guardrail | 100% local processing |
| Resource requirement | High (GPU/NPU), substantial RAM; not for Edge AI | Low; design for Edge AI |
| Availability | Need internet connection | 100% offline |
| User experience impact | Yes | User undetectable |
| Continuously automotive and AI attack techniques updated | Limited, no dedicated security threat intelligence | Supported by VicOne automotive threat intelligence |
xPhinx FAQ
What is VicOne xPhinx?
Why can't cloud-based AI guardrails protect in-vehicle AI?
How does xPhinx protect in-vehicle AI without slowing it down?
What AI threats does xPhinx defend against?
Does xPhinx require changes to existing AI models?
Can xPhinx be deployed across different AI frameworks and operating systems?
How does xPhinx support automotive compliance?
Know More From Our Resources
GAIN INSIGHTS INTO AUTOMOTIVE CYBERSECURITY

Shifts in the Supply Chain: How Ransomware Targets Global Logistics Fleets
VicOne CyberThreat Research Lab identifies key vulnerability classes in fleet-related applications, underscoring the need for stronger security across connected fleet platforms.
READ MORE →
What Commercial Fleet Operators Should Know About ELD Data Integrity
VicOne's CyberThreat Research Lab review of common Android ELD apps shows why commercial fleets should look beyond the dashboard and treat ELD data integrity as a security priority.
READ MORE →
Attack Surfaces from Pwn2Own Automotive 2026: Key Findings for Security Teams
This blog highlights three attack surfaces from Pwn2Own Automotive 2026 and what they reveal about emerging risks in EV chargers, IVI systems, and connected vehicle security.
READ MORE →
Prerequisites for Vulnerability Management in Automotive Cybersecurity in the AI Era
As AI accelerates exploit development, CVSS scores alone no longer suffice. Here's what automotive OEMs and suppliers must prioritize now.
READ MORE →